반응형
0. 개요
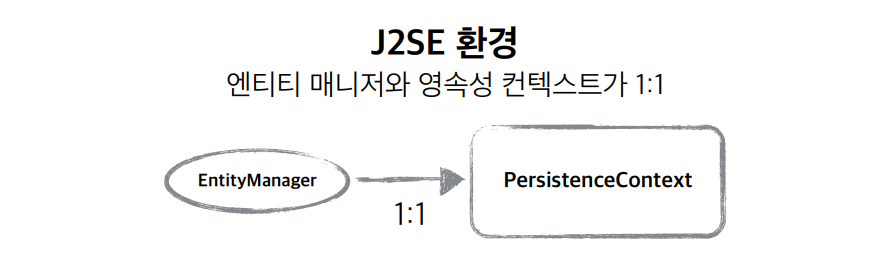
지난 시간에는 JPA의 핵심 구조인 영속성 컨텍스트와 엔티티 생명주기에 대해 알아봤습니다.
이번에는 영속성 컨텍스트가 우리에게 어떤 실질적인 장점을 제공하는지 하나씩 살펴보겠습니다.
1. 1차 캐시 (First-Level Cache)
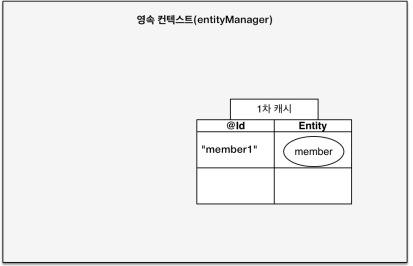
영속성 컨텍스트는 엔티티를 관리하기 위해 메모리 캐시(1차 캐시) 를 내부에 가지고 있습니다.
이 캐시는 같은 트랜잭션 범위 안에서 반복되는 조회를 줄여주는 역할을 합니다.
// 엔티티를 생성한 상태 (비영속)
Member member = new Member();
member.setId("member1");
// 영속 상태 (1차 캐시에 저장)
em.persist(memeber);
// 1차 캐시에서 조회 (DB에서 조회하지않음)
Member findM = em.find(Member.class, "member1");
- persist() 시점에서 1차 캐시에 저장됨
- 이후 find()를 하면 DB가 아니라 캐시에서 조회
- 복잡한 도메인 로직에서 중복 조회를 줄여주는 데 유용
2. 엔티티 동일성 보장 (Identity Guarantee)
JPA는 같은 트랜잭션 범위 내에서 같은 엔티티는 동일한 인스턴스로 보장합니다.
Member m1 = em.find(Member.class, 1);
Member m2 = em.find(Member.class, 1);
System.out.println(a == b); // true 동일성 보장- 두 객체는 equals() 비교가 아닌 == 비교에서도 true
- 즉, 같은 1차 캐시 객체를 반환
- 이는 도메인 모델을 안전하게 다루고, ORM의 객체 그래프 관리에 있어 중복 문제를 방지해줌
3. 트랜잭션을 지원하는 쓰기 지연
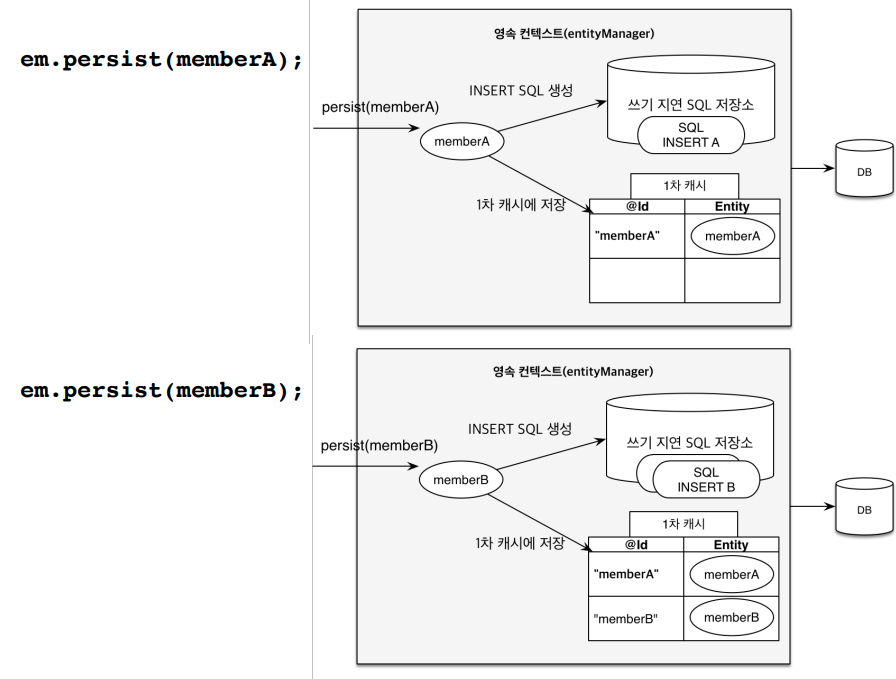
JPA는 persist() 시점에 곧바로 DB에 INSERT 쿼리를 날리지 않습니다.
대신 내부의 쓰기 지연 저장소(write-behind queue) 에 SQL을 모아뒀다가,
commit() 시점에 한꺼번에 DB에 반영합니다.
transaction.begin(); // 트랜잭션 시작
em.persist(member1);
em.persist(member2); // 영속 상태 (쿼리 날리지 않음)
// 커밋하는 시점에 INSERT SQL을 보냄
trasaction.commit();
- INSERT 쿼리를 모아서 한번에 처리
- DB와의 통신 횟수를 줄여줌 → 성능 최적화
- Hibernate는 이걸 Batch Insert로 활용할 수도 있음 (설정 필요)
4. 변경 감지 (Dirty Checking)
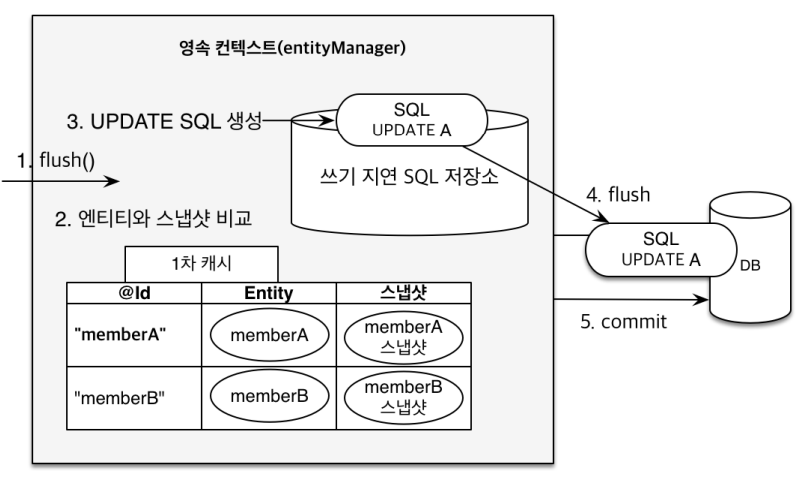
JPA는 영속성 컨텍스트 안의 엔티티가 변경되면
자동으로 UPDATE SQL을 생성해서 DB에 반영합니다.
trasaction.begin();
// 영속 엔티티 조회
Member m = em.find(Member.class, 1);
// 영속 엔티티 수정
m.setUsername("name2");
trasaction.commit();- 영속성 컨텍스트에 엔티티가 등록될 때 스냅샷(초기 상태 복사본) 을 저장
- 트랜잭션 종료 전 현재 값과 스냅샷을 비교
- 변경된 필드가 있다면 → UPDATE SQL 생성
- 이 쿼리도 마찬가지로 쓰기 지연 저장소에 모았다가 커밋 시 DB 반영
이걸 Dirty Checking이라고 부릅니다.
5. 지연로딩
추후 작성 예정
반응형
'프로그래밍 > JPA' 카테고리의 다른 글
| [JPA] 필드와 컬럼 매핑 (1) | 2025.06.19 |
|---|---|
| [JPA] 데이터베이스 스키마 자동 생성 (0) | 2025.06.19 |
| [JPA] 객체와 테이블 매핑 (0) | 2025.06.19 |
| [JPA] JPA 의 영속성 관리 (0) | 2025.06.10 |
| [JPA] JPA 동작 방식 (2) | 2025.06.08 |