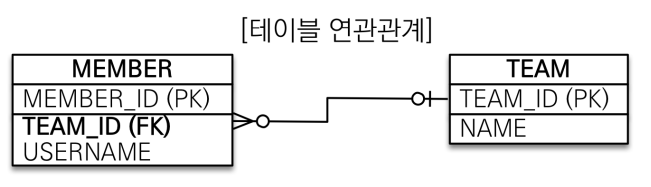
1. 다대일 단방향 (@ManyToOne)
실무에서 가장 많이 사용하는 구조
외래키가 N(다)쪽 테이블에 존재
DB와 객체 매핑이 가장 자연스럽고, 성능/유지보수/조회 모두 장점

코드로는?
@Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}정리
DB입장에서 다에 외래키가 가야함, @ManyToOne 맴버 입장에서 팀찾기 위해 Team을 매핑함
그니까 즉외래키가 있는곳에 (ManyToOne) 매핑하면됨
- DB 기준: N쪽에 외래키가 가야함 (member 테이블에 team_id 외래키)
- @ManyToOne 어노테이션 사용
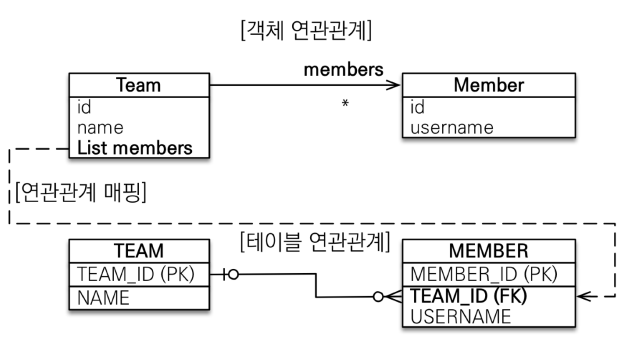
2. 다대일 양방향 (@ManyToOne + @OneToMany)
Member 뿐 아니라, Team에서 member 조회 필요할 때
실제 연관관계의 주인은 외래키가 있는 곳(N쪽)
즉, @ManyToOne이 항상 주인, @OneToMany(mappedBy = "team_id")는 읽기용

코드 예시
@Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
//@Column(name = "TEAM_ID")
//private Long teamId;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}@Entity
public class Team {
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany(mappedBy = "team") // 읽기전용, 주인 아님
private List<Member> members = new ArrayList<>();
}
3. 일대다 단방향 (@OneToMany Only)
1쪽(Team)이 연관관계의 주인 (멤버입장에서 팀을 알필요가 없을 때)
1쪽(Team)에 외래키 관리 책임이 생김 → 비효율
JPA 표준 스펙은 지원하지만, 실무에서는 추천 안함
하지만 DB 설계 자체는 Member쪽에 외래키가 들어가야함
@Entity
public class Team {
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
@OneToMany
@JoinColumn(name = "TEAM_ID")
private List<Member> members = new ArrayList<>();
} @Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
}Member member = new Member();
member.setUsername("member1");
em.persist(member); // insert member
Team team = new Team(); // insert team
team.setName("teamA");
team.getMembers().add(member); // update Member set TEAM_ID = ? WHERE MEMBER_ID=?
- 동작:
- team.getMembers().add(member) 시
- 실제로는 update 쿼리 1번 더 나감
(update Member set TEAM_ID = ? where MEMBER_ID = ?)
- 비추천 이유:
- 실질적으로 외래키는 항상 N쪽(Member)에 있으므로 update쿼리가 한번 더 나가서 성능상 손해
- 1쪽(Team)이 외래키 관리 = 성능 손해, 객체지향적으로도 어색 (team을 수정했는데 > member테이블을 수정하는 쿼리 요청)
- 조인컬럼을 꼭 써야함, 그렇지 않으면 조인 테이블 방식을 사용해버림
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
// 조인컬럼 명시 안 함!
@OneToMany
private List<Member> members = new ArrayList<>();
}
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
private String username;
}
create table team (
id bigint not null,
name varchar(255),
primary key (id)
);
create table member (
id bigint not null,
username varchar(255),
primary key (id)
);
-- <== JPA가 만든 중간 테이블!
create table team_members (
team_id bigint not null,
members_id bigint not null,
primary key (team_id, members_id)
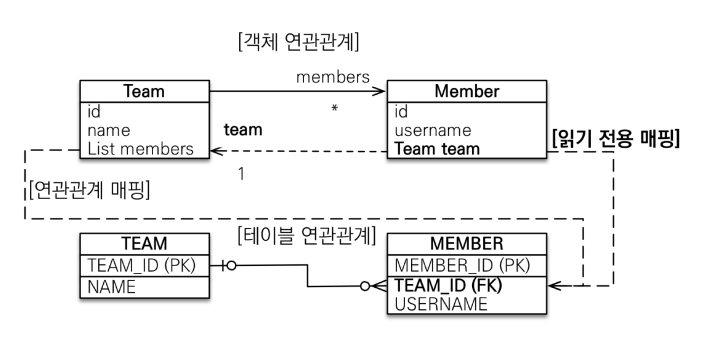
);4. 일대다 양방향 (거의 안 씀, 읽기전용 트릭)
사실상 쓸 일 없음. 읽기전용 컬렉션이나, 조인 쿼리/화면용
insertable=false, updatable=false 옵션 활용
@Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable = false, updateable = false)
private Team team;
}이런 식:
- insertable, updateable 옵션으로 읽기전용으로 사용 가능 (필수)
- 읽기 전용으로 사용하지 않을경우 양방향으로 수정이 가능해서 운영상 큰 문제가 생길 수 있음
- 하지만 그냥 이구조는 사용하지 말자
- 사실상 데이터 일관성 보장 어렵고, 양방향 필요하면 다대일 양방향 구조 사용 권장
5. 일대일 매핑
DB입장에서 일대일 매핑의 경우 외래키는 양쪽 모두 가능하다.
즉 일대일 관계의 반대도 일대일 매핑이다. (외래키에는 UNI 제약조건이 필요하다)
외래키를 주 테이블(Member)에 둘 경우

@Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable = false, updateable = false)
private Team team;
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
}@Entity
public class Locker {
@Id @GeneratedValue
private Long id;
private String name;
//@OneToOne(mappedBy = "locker") 양방향 매핑이 필요한 경우 mappedBy로 읽기전용 매핑
//private Member member;
}
정리:
- 다대일 양방향 매핑처럼 외래키가 있는 곳이 연관관계의 주인
- 반대편은 mappedBy 사용
외래키를 대상 테이블(Locker)에 둘 경우
JPA에서 Member에 Locker를 두는 경우는 지원하지 않는다.
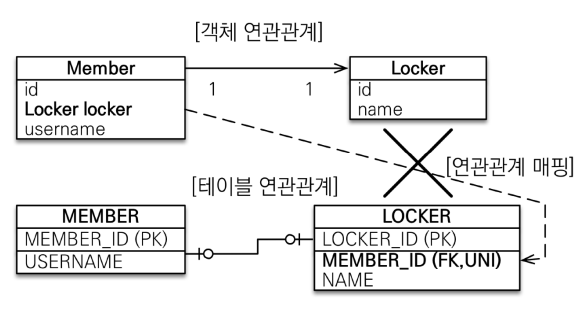
즉, 단방향 연관관계에서는 항상 주 테이블이 외래 키를 가지고 있어야 합니다.
하지만 이런 양방향 관계는?
가능하다 Locker의 멤버를 외래키의 주인으로 둔다 (위쪽을 반대로 바꾼상황)

그럼 외래 키를 어디에 두는 게 좋을까?
DBA 관점
- 정책이 바뀔 가능성 고려 (ex. 나중에 Member가 여러 개의 Locker를 가질 수도 있음)
- 이 경우 외래 키를 **대상 테이블(Locker)**에 두고, UNIQUE 제약만 제거하면 1:N 구조로 쉽게 확장 가능
- 반면 Member 쪽에 FK가 있으면 컬럼 삭제 및 스키마 변경 필요 → 유지보수 부담 증가
- 데이터 모델의 유연성 확보에 유리
📌 선호: 외래 키를 **대상 테이블(Locker)**에 둔다.
ORM/JPA 개발자 관점
- 대부분의 비즈니스 로직은 **Member(주 테이블)**를 중심으로 조회됨
- Member에서 Locker 존재 유무에 따라 로직 분기가 많음
→ 쿼리 하나로 Locker 존재 여부 확인 가능 - JPA 매핑이 쉬움
- 성능상 이점 (불필요한 조인 생략 가능)
- 📌 권장: 외래 키를 **주 테이블(Member)**에 둔다. (하지만 업무환경에 맞게...)
정리
주 테이블(주로 많이 접근하는 테이블)의 외래키
- 주 객체가 대상 객체의 참조를 가지는 것 처럼 주 테이블에 외래키를 두고 대상 테이블을 찾음
- JPA 매핑 편리
- 주 테이블만 조회해도 대상 테이블의 데이터가 있는지 확인 가능 (member만 조회해도 locker의 유무를 알 수 있음)
만약 Locker값이 없으면 외래 키에 null을 허용해야한다는 단점이 있음
대상 테이블에 외래 키
- 주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변경할 때 테이블 구조 유지가능
프록시 기능의 한계로 지연로딩으로 설정해도 항상 즉시 로딩된다.
6. 다대다 매핑 (N:M) (실무에서 쓰면 안됨)
관계형 데이터베이스는 정규화된 테이블 2개로 다대다 관계를 표현할 수 없음
연결 테이블을 추가해서 일대다, 다대일 관계로 작성해야함

하지만 객체는 컬렉션을 사용해서 객체 2개로 다대다 관계 가능 (즉 객체관계를 아래 테이블 구조로 만들어준다)

예제 코드
@Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable = false, updateable = false)
private Team team;
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
// 해당 부분
@ManyToMany
@JoinTable(name = "MEMBER_PRODUCT")
private List<Product> products = new ArrayList<>();
}@Entity
public class Product {
@Id @GeneratedValue
private Long id;
private String name;
// 양방향으로 쓸경우 해당 부분 작성
@ManyToMany(mappedBy = "roducts")
private List<Member> members = new ArrayList<>();
}실무에서 사용하면 안 되는 이유
굉장히 편해보이는데?
실제 운영 환경에서는 연결테이블이 단순하게 연결만 하고 끝나지 않고, 추가정보들을 필요로 한다.
ex) ORDERAMUNT, ORDERDATE...등
1. ManyToMany의 경우 중간 테이블에 추가 정보를 넣을 수 없다
2. 쿼리 구조가 비직관적
JPA가 생성하는 SQL이 다음과 같은 형태로 나가게 됩니다
Member 자체를 조회후 아래와 같은 2번의 쿼리를 실행한다.
select * from member_product where member_id = ?
select * from product where id in (?, ?, ?, ...)
- join 없이 2번의 쿼리 실행
- 추가 필터 조건이나 정렬이 어렵고,
- 중간 테이블을 조작할 수 없음
왜 JOIN이 아닌가?
JPA에서 @ManyToMany는 **중간 테이블(member_product)**을 직접 엔티티로 취급하지 않고, 그냥 연결 매핑용 메타 정보만 활용하기 때문에 join하지 않고 2단계 접근합니다.
JPA는 연관 관계를 객체 기준으로 관리하기 때문에 단방향/양방향 여부와 Lazy/Eager 여부에 따라 내부 쿼리가 달라지지만, 대부분 @ManyToMany + LAZY 조합은 중간 테이블 → 대상 테이블 IN 절 조회 구조로 됩니다

실무에서의 해결 방법: 중간 엔티티로 승격
중간 테이블을 엔티티(MemberProduct)로 만들어 명시적으로 다뤄야 합니다.
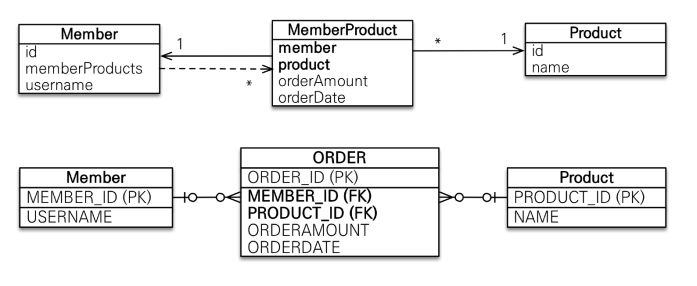
@Entity
public class Member {
@Id @GeneratedValue
@Column("MEMBER_ID")
private Long id;
@Column(name = "USERNAME")
private String name;
// 해당 부분
@OneToMay(mappedBy="member")
private List<MemberProduct> memberProducts = new ArrayList<>();
}@Entuty
public class MemberProduct {
@Id @GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name="MEMBER_ID")
private Member member;
@ManyToOne
@JoinColumn(name="PRODUCT_ID")
private Product product;@Entity
public class Product {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "product")
private List<MemberProduct> memberProduct = new ArrayList<>();
}장점
- orderDate, orderAmount 등 추가 컬럼 관리 가능
- 비즈니스 로직에서 MemberProduct 자체를 조작 가능
- 복잡한 조회 조건, 정렬 등도 자유롭게 작성 가능
- 쿼리 최적화 가능 (JOIN, INDEX, FETCH 등)
'프로그래밍 > JPA' 카테고리의 다른 글
| [JPA] Mapped Superclass - 매핑 정보 상속 (0) | 2025.07.03 |
|---|---|
| [JPA] 상속관계 매핑 (2) | 2025.07.03 |
| [JPA] 양방향 연관관계와 연관관계의 주인[2] (0) | 2025.06.25 |
| [JPA] 양방향 연관관계와 연관관계의 주인[1] (1) | 2025.06.24 |
| [JPA] 단방향 연관관계 (0) | 2025.06.24 |