1. 캐시 스탬피드 현상이란?
캐시 만료 시점에 대량의 요청이 한꺼번에 DB 또는 외부 API 등 원본 소스로 몰리는 현상입니다.
“동시에 캐시가 비어, 수많은 트래픽이 원본 시스템을 두드려
서비스 전체의 가용성과 응답속도를 위협하는 상황”
✅ 일반적인 캐시 동작 플로우
1. 클라이언트가 데이터를 요청
2. 서버는 캐시에서 해당 데이터를 조회
3. 캐시에 존재하면 그 값을 바로 반환
4. 캐시에 없으면 (Miss) → DB나 외부 API 등 원본 시스템에서 조회 후 캐시에 저장, 응답
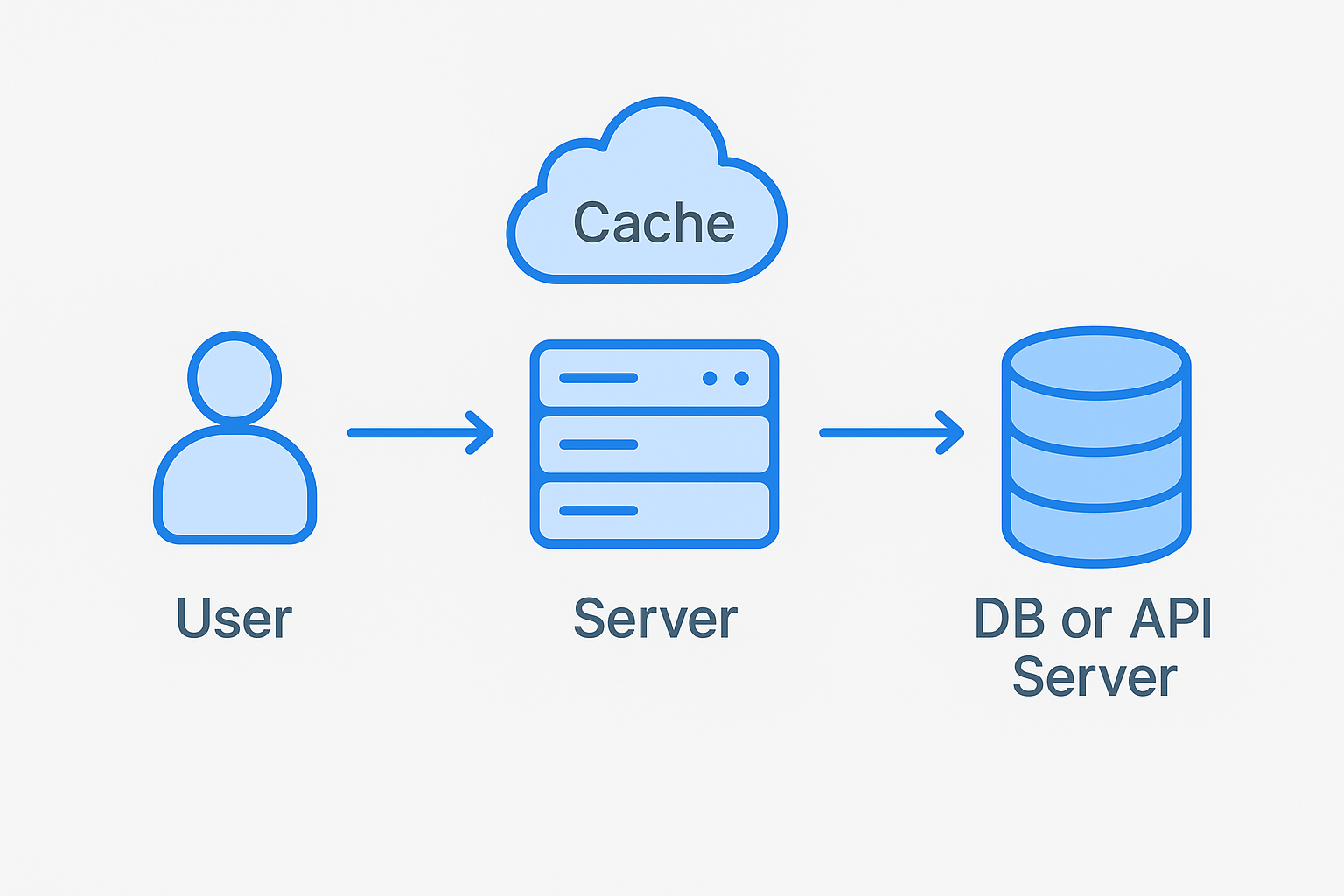
🚨문제가 생기는 경우: 캐시 만료 시점
예를 들어 캐시가 만료된 시점에 동시에 N건의 요청이 들어오면 어떻게 될까?
- 캐시 데이터가 만료되었고, 이 때 100만명의 사용자가 요청을 진행함
- 100만건 요청 모두 DB or API 서버로 데이터를 요청
- 특별한 조치가 없을 경우, 백엔드 서버는 100만번 캐시에 기록 후 사용자에게 데이터를 전달
이런 경우 백엔드, 캐시 모두 부하(장애, 응답 지연, 전체 다운 위험)를 일으키는 원인이 되며
이러한 현상을 캐시 스탬피드라고 합니다.
2. 해결 방법
2-1. TTL (Time To Live) 증가
캐시 만료 주기를 늘리면, 실제 리소스에 접근하는 횟수를 줄이고 위험도 줄어듭니다. (가장 간단한 방법)
단점:
- 실시간성이 중요한 경우 사용자 경험이 나빠질 수 있음
- 예) 어떤 상품이 오전 10시부터 판매일때, 10시 2분에도 아직 오래된 캐시로 사용자에게 판매 대기중으로 보일 수 있음
2-2. Lock을 통한 동시성 제어
하나의 요청에 Lock을 걸어 동시에 캐시를 쓰지 않도록 하여 단한번의 캐시 쓰기 작업만 이루어지도록 한다
AOP 구현
@Aspect
@Component
@RequiredArgsConstructor
@Slf4j
public class DistributedLockAop {
private static final String LOCK_PREFIX = "LOCK:";
private final RedissonClient redissonClient;
@Around("@annotation(distributedLock)")
public Object lock(ProceedingJoinPoint joinPoint, DistributedLock distributedLock) throws Throwable {
String key = LOCK_PREFIX + parseKey(joinPoint, distributedLock.key());
RLock lock = redissonClient.getLock(key);
boolean locked = false;
try {
locked = lock.tryLock(
distributedLock.waitTime(),
distributedLock.leaseTime(),
distributedLock.timeUnit()
);
if (!locked) {
// 락 획득 실패시 예외 또는 커스텀 반환
log.warn("분산락 획득 실패: {}", key);
throw new IllegalStateException("Lock acquisition failed: " + key);
}
// 비즈니스 로직 실행
return joinPoint.proceed();
} finally {
if (locked && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
private String parseKey(ProceedingJoinPoint joinPoint, String keyExpression) {
// 파라미터를 SpEL로 파싱하는 유틸 (아래 참고)
return CustomSpringELParser.getDynamicValue(
((MethodSignature) joinPoint.getSignature()).getParameterNames(),
joinPoint.getArgs(),
keyExpression
).toString();
}
}
캐시 조회 / 갱신 서비스 구현
@Service
@RequiredArgsConstructor
public class ProductService {
private final RedisTemplate<String, Object> redisTemplate;
private final ProductRepository productRepository;
@DistributedLock(key = "'product:' + #productId")
public Product getProductWithCache(Long productId) {
String cacheKey = "product:" + productId;
Product product = (Product) redisTemplate.opsForValue().get(cacheKey);
if (product == null) {
// 캐시 미스 → 락 잡은 1명만 이 코드에 진입
product = productRepository.findById(productId)
.orElseThrow(() -> new RuntimeException("상품 없음"));
redisTemplate.opsForValue().set(cacheKey, product, 5, TimeUnit.MINUTES);
}
return product;
}
}
단점
- 결국 Lock걸린 작업이 끝날때까지 대기해야한다.
2-3. 캐시 웜업 (캐시 사전로딩)
별도의 배치(30초, 1분 등)를 통해서 많은 트래픽이 발생할 수 있는 캐시를 캐시가 만료되기 전에 미리 갱신해주는 방법
만료되기전 미리 갱신하므로 캐시에 있는 데이터만으로 조회하고, 트래픽 부하에 대비하고 응답지연현상도 방지할 수 있음
문제점
- 캐시로 넣어야하는 데이터를 미리 예측하지 못할경우 누락 가능
- 대량 데이터 갱신시, 부하 가능성 존재
🚩 카카오 프로모션 캐시 운영의 실제 이슈
카카오에서는 상품 프로모션 정보를 약 22,000개 운영 중입니다.
만약 이 모든 데이터를 캐시 웜업(warm-up) 방식으로 미리 메모리에 올리면
- 최악의 경우 30GB라는 엄청난 캐시 공간이 소모되고
- 전체 웜업에도 오랜 시간이 걸립니다.
2-4. PER (확률적 조기 갱신) 방식
PER 동작 원리
- 캐시의 실제 TTL보다 조금 더 일찍, 일정 확률로 갱신
- 예를 들어 TTL 10분짜리 캐시라면 9분부터 10분 사이에 들어오는 요청들은 확률적으로 캐시를 갱신함
- 이때 "얼마나 확률적으로 조기갱신 할 것인가"를 수학적 "PER 공식"으로 계산
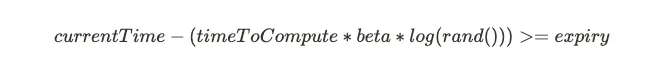
- currentTime: 현재시간 (currentTimeMillis)
- timeToCompute(Recompute time interval, delta): 캐시된 값을 다시 계산하는데 걸리는 시간
- beta: 기본적으로 1. 0보다 큰 값 설정 가능. 갱신이 자주 일어나길 바랄 경우 beta를 수정하여 확률을 높일 수 있다.
- rand(): 0과 1 사이의 랜덤 값을 반환하는 함수. log(rand())¹의 값은 0부터 마이너스 무한대까지의 범위를 가짐.
- expiry (that is, time() + pttl)
@RestController
@RequiredArgsConstructor
public class ProductController {
private final ProductService productService;
@GetMapping("/products/{productId}")
public ResponseEntity<ProductDto> getProduct(@PathVariable Long productId) {
ProductDto product = productService.getProductWithPERCache(productId);
return ResponseEntity.ok(product);
}
}
@Service
@RequiredArgsConstructor
public class ProductService {
private final CacheManager cacheManager;
private final ProductRepository productRepository;
// PER 파라미터
private final long TIME_TO_COMPUTE_MS = 100; // DB조회 예상시간 (ms)
private final double BETA = 1.0;
public ProductDto getProductWithPERCache(Long productId) {
Cache cache = cacheManager.getCache("productCache");
ProductCacheValue cached = cache.get(productId, ProductCacheValue.class);
long now = System.currentTimeMillis();
if (cached != null) {
// PER 공식 적용
long expiry = cached.getExpiry(); // 캐시 만료 시각
double rand = Math.random(); // 0~1
double lhs = now + TIME_TO_COMPUTE_MS * BETA * Math.log(rand);
// 캐시 만료 전이라도, 확률적으로 갱신
if (lhs < expiry) {
return cached.getProduct();
}
// 아니면 DB에서 새로 조회
}
// DB 조회 및 캐시 갱신
ProductDto product = productRepository.findById(productId)
.orElseThrow(() -> new EntityNotFoundException("Not Found"));
// 캐시 저장 (예: TTL 5분)
long newExpiry = now + 5 * 60 * 1000;
cache.put(productId, new ProductCacheValue(product, newExpiry));
return product;
}
}
- 캐시에 데이터가 있으면
PER 수식 계산
now + timeToCompute * beta * log(rand()) < expiry
만족하면 캐시 리턴, 아니면 새로 갱신 - 캐시에 없으면 무조건 DB 조회 후 캐시 저장
- TTL(만료시각)은 value에 함께 기록, 실전에서는 Redis 등과 조합하면 더 견고
- 스탬피드 현상 최소화
- Hot data 예측/분산 효과
- “적은 비용으로 큰 효과” (특히 대형 트래픽 서비스에서)
단점/주의
- 확률식과 TTL/요청도에 따라 실제 조기갱신이 과도하거나 부족할 수 있음
- 퍼포먼스 튜닝 필요
....
[실제 테스트 결과 분석] 미반영
1. 응답시간
CPU
Cache Hit
Cache Miss
CacheHit Rate
'프로그래밍 > SpringBoot' 카테고리의 다른 글
| RestDoc과 Swagger 함께 사용하기 (1) | 2025.05.29 |
|---|---|
| [Spring boot] @Transactional의 예외처리 (checked, Unchecked Exception) (0) | 2022.11.16 |
| [spring security] csrf와 jwt의 관계 (0) | 2022.11.14 |
| [Spring boot 강의] #2 스프링부트 HTTPS / HTTP2적용하기 (0) | 2020.03.05 |
| [Spring boot 강의] #1 Spring Boot 프로젝트 실행하기 (0) | 2020.02.27 |