Spring Batch 전체 구조를 이해하기 전에
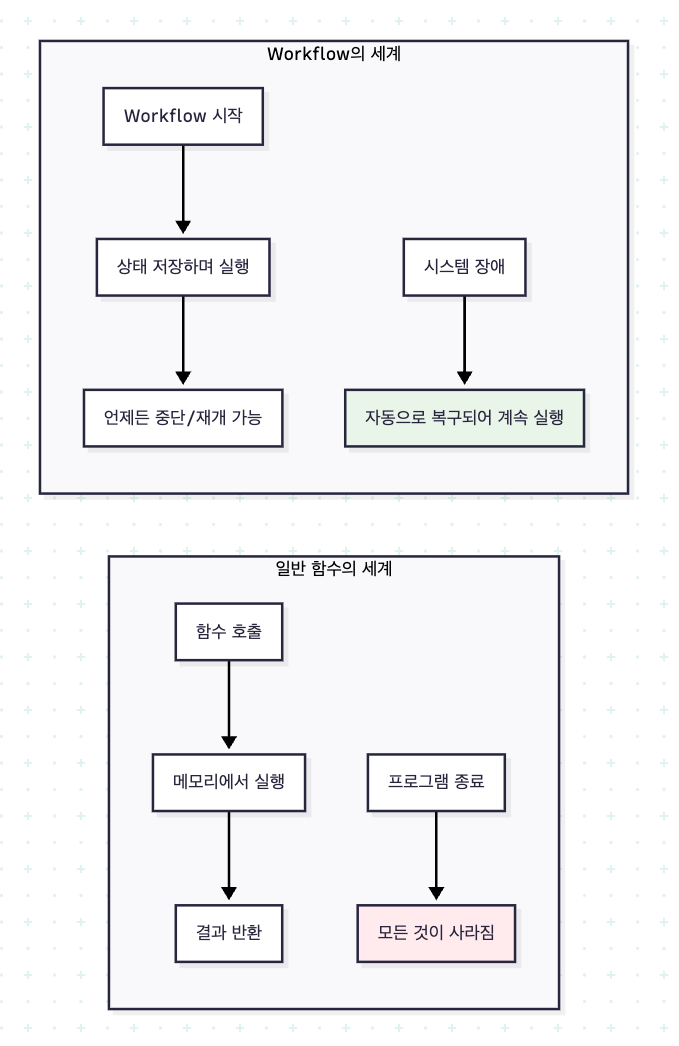
Spring Batch는 단순히 “데이터를 읽고-쓰는 도구”가 아니다.
Job → Step → Reader/Processor/Writer로 이어지는 표준 처리 플로우를 중심으로,
실행/재시작/상태 관리까지 포함한 하나의 배치 실행 플랫폼이다.
이 시스템을 제대로 이해하려면 먼저 가장 핵심적인 두 개념부터 잡아야 한다.
Job과 Step
Job — 배치 처리의 최상위 단위
하나의 Job은 “하나의 배치 작업 전체”를 의미한다.
- 매일 0시에 실행되는 '일일 매출 집계'
- 매주 일요일마다 처리되는 '휴면 회원 정리'
- 매월 1일에 실행되는 '정기 결제'
- 필요시점에 실행하는 '대용량 데이터 이관'
즉, Job은 “무엇을 처리할 것인가”를 가장 큰 단위에서 정의한다.
Step — Job을 구성하는 실행 단위
Step은 Job을 구성하는 실행 단위로 하나의 Job은 하나 이상의 Step으로 구성된다. 예를 들어 '일일 매출 집계' Job은 다음과 같은 Step들로 이뤄질 수 있다.
1. 매출 집계 Step
- 전일 주문 데이터를 읽고(read)
- 결제 완료된 것만 필터링하여(process)
- 상품별/카테고리별로 집계해서 저장(write)
2. 알림 발송 Step
- 집계 요약 정보를 생성하여 관리자에게 전달
3. 캐시 갱신 Step
- 집계된 데이터로 캐시 정보 업데이트
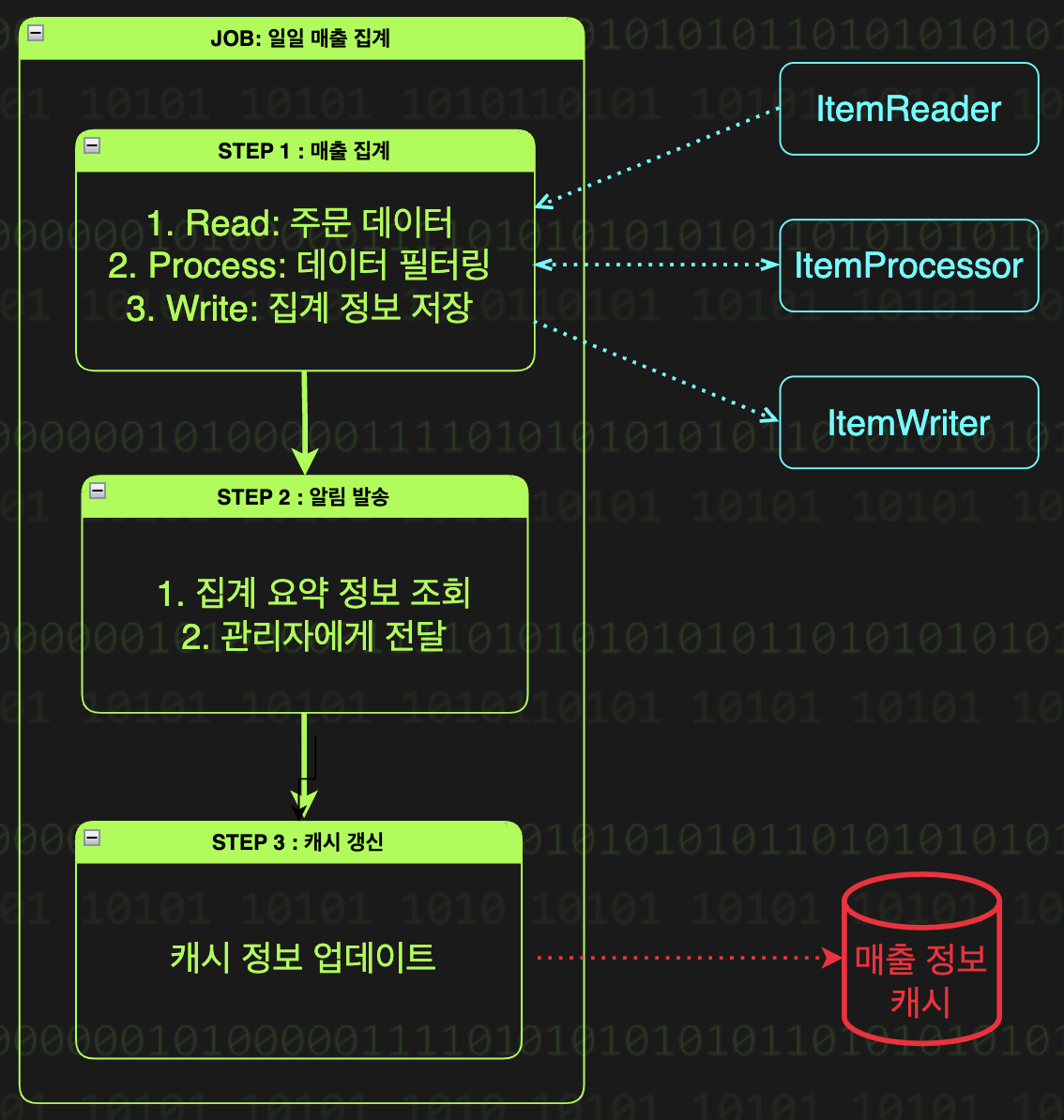
각 Step은 순차적으로 실행되며,
이 중 하나라도 실패하면 Job은 실패한다.
Spring Batch 시스템을 이해하는 관점
Spring Batch는 크게 두 가지 영역으로 나눠 보면 훨씬 이해가 쉽다.
✔ Spring Batch가 제공하는 영역
- Job / Step API (JobBuilder, StepBuilder)
- JobLauncher: Job을 실행하고 실행에 필요한 파라미터를 전달하는 역할을 한다. 배치 작업 실행의 시작점이라고 할 수 있다.
- JobRepository: 배치 처리의 모든 메타데이터를 저장하고 관리하는 핵심 저장소로 Job과 Step의 실행 정보(시작/종료 시간, 상태, 결과 등)를 기록한다. 이렇게 저장된 정보들은 배치 작업의 모니터링이나 문제 발생 시 재실행에 활용된다.
- ExecutionContext: Job과 Step 실행 중의 상태 정보를 key-value 형태로 담는 객체다. Job과 Step 간의 데이터 공유나 Job 재시작 시 상태 복원에 사용된다
- 데이터 처리 컴포넌트 구현체: 앞서 0장에서 설명했듯이 Spring Batch는 데이터를 '읽기-처리-쓰기' 방식으로 처리하며, 이를 위한 다양한 구현체를 제공한다.
- ItemReader 구현체: JdbcCursorItemReader, JpaPagingItemReader, MongoCursorItemReader 등 다양한 데이터 소스로부터 데이터를 읽어올 수 있다.
- ItemWriter 구현체: JdbcBatchItemWriter, JpaItemWriter, MongoItemWriter 등을 통해 처리된 데이터를 저장할 수 있다.
이 영역은 프레임워크가 책임진다.
우리는 “조합해서 사용”만 하면 된다.
✔ 개발자가 제어하는 영역
- @Configuration을 사용해 Job과 Step의 실행 흐름을 정의한다.
- 각 Step의 실행 순서와 조건을 설정하고, Spring 컨테이너에 등록해 배치 잡의 동작을 구성한다.
- Spring의 DI(의존성 주입)를 활용해 ItemReader, ItemProcessor, ItemWriter 등 배치 작업에 필요한 컴포넌트들을 조합하고 배치 플로우를 완성한다.
- 아래 예제는 가장 간단한 형태의 Spring Batch 잡 구성 코드를 보여준다. 이처럼 개발자는 Job과 Step을 빈으로 정의하고, 필요한 ItemReader와 ItemWriter를 조합해 배치 흐름을 구성하기만 하면 된다.
@Bean
public Job dataTerminationJob(Step terminateStep) {
return new JobBuilder("dataTerminationJob", jobRepository)
.start(terminateStep)
.build();
}
@Bean
public Step terminateStep(ItemReader<String> itemReader, ItemWriter<String> itemWriter) {
return new StepBuilder("terminateStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader)
.writer(itemWriter)
.build();
}
@Bean
public ItemReader<String> itemReader() {
// return ItemReader 구현체
}
@Bean
public ItemWriter<String> itemWriter() {
// return ItemWriter 구현체
}즉, 비즈니스 로직 자체에만 집중하면 되고,
실행/상태관리/재시작 같은 복잡한 인프라는 Batch가 전담한다.
Spring Boot 기반 구성만 남긴 이유
Spring Batch는 순수 Spring으로도 구성할 수 있지만
실제로는 Spring Boot 기반으로 사용하는 경우가 99%다.
이유:
- JobRepository, TransactionManager, DataSource 자동 구성
- JobLauncherApplicationRunner 자동 실행
- H2 같은 기본 메타데이터 DB 자동 초기화
결론: Spring Boot면 바로 로직부터 작성할 수 있다.
그렇기 때문에 원본 글의 “순수 Spring 설정” 부분은 전부 제거하고
여기서는 Spring Boot 기준만 정리한다.
Spring Boot 기반 Spring Batch 기본 구조
아래는 Boot 환경에서 가장 기본적인 Batch 설정 흐름이다.
1) Job/Step 구성
@Configuration
public class SystemTerminationConfig {
private final JobRepository jobRepository;
private final PlatformTransactionManager transactionManager;
private AtomicInteger processesKilled = new AtomicInteger(0);
private final int TERMINATION_TARGET = 5;
public SystemTerminationConfig(JobRepository jobRepository,
PlatformTransactionManager transactionManager) {
this.jobRepository = jobRepository;
this.transactionManager = transactionManager;
}
@Bean
public Job systemTerminationSimulationJob() {
return new JobBuilder("systemTerminationSimulationJob", jobRepository)
.start(enterWorldStep())
.next(meetNPCStep())
.next(defeatProcessStep())
.next(completeQuestStep())
.build();
}Spring Boot는 JobRepository와 TransactionManager를 자동 설정해주기 때문에
우리는 생성자 주입만 하면 된다.
2) Step 정의
Step 1
@Bean
public Step enterWorldStep() {
return new StepBuilder("enterWorldStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("System Termination 시뮬레이션 세계에 접속했습니다!");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}Step 2
@Bean
public Step meetNPCStep() {
return new StepBuilder("meetNPCStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("시스템 관리자 NPC를 만났습니다.");
System.out.println("첫 번째 미션: 좀비 프로세스 " + TERMINATION_TARGET + "개 처형하기");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
Step 3 (반복 Step)
@Bean
public Step defeatProcessStep() {
return new StepBuilder("defeatProcessStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
int terminated = processesKilled.incrementAndGet();
System.out.println("좀비 프로세스 처형 완료! (" + terminated + "/" + TERMINATION_TARGET + ")");
return terminated < TERMINATION_TARGET
? RepeatStatus.CONTINUABLE
: RepeatStatus.FINISHED;
}, transactionManager)
.build();
}@Bean
public Step completeQuestStep() {
return new StepBuilder("completeQuestStep", jobRepository)
.tasklet((contribution, chunkContext) -> {
System.out.println("미션 완료!");
return RepeatStatus.FINISHED;
}, transactionManager)
.build();
}
Spring Boot에서 배치 실행
실행 방법
./gradlew bootRun --args='--spring.batch.job.name=systemTerminationSimulationJob'JobLauncherApplicationRunner가 spring.batch.job.name프로퍼티에 지정된 Job을 찾아 실행해준다.
실행 흐름 정리
- JobRepository와 필수 인프라가 Boot 자동 설정으로 구성됨
- Job/Step만 등록하면 됨
- bootRun 시 JobLauncherApplicationRunner가 Job 실행
- Step 순서대로 실행
- 상태/메타데이터는 DB(H2 등)에 자동 저장
핵심 정리
- Spring Batch는 Job 단위의 배치 실행 플랫폼
- Job은 Step들의 묶음
- Step은 tasklet 또는 chunk 기반
- Boot 환경에서는 인프라 전부 자동 구성
- 개발자는 로직 + Reader/Writer 설정만 담당
- 실행은 --spring.batch.job.name로 제어
- 재시작/상태관리/에러복구는 Batch가 자동 처리
'프로그래밍 > Spring' 카테고리의 다른 글
| [Spring Batch] 배치처리란 무엇인가? (1) | 2025.12.07 |
|---|---|
| [Spring Security] 스프링 시큐리티(Spring Security) 사용시 주의 사항 (0) | 2021.12.06 |
| [Kotlin] 코틀린이란? 코틀린과 자바의 차이 (0) | 2021.04.27 |
| [스프링 강의] #11 스프링 시큐리티란? / spring security (0) | 2020.02.21 |
| [스프링 강의] #10 스프링 MVC패턴 실습 / spring MVC / MVC란? (0) | 2020.01.29 |