대용량 트래픽 처리 시스템이란?
- 하나의 서버, 데이터베이스로 감당하기 힘든 부하를 처리하는것 > 다수의 서버와 데이터베이스를 마치 하나인것처럼 동작하게한다 (이안에는 여러 마이크로서비스들 포함)
대용량 트래픽 처리를 위한 특징 세가지
1. 고가용성
- 언제든 서비스를 이용할 수 있어야함
2. 확장성
- 시스템이 비대해짐에 따라 증가하는 데이터와 트래픽에 대응할 수 있어야한다.
3. 관측 가능성
- 문제가 생겼을 때 빠르게 인지할 수 있어야하고 문제의 범위를 최소화 할 수 있어야함
앞서 DB의 병목현상에 대해 알아봤는데, 점진적으로 대용량 트래픽 처리 시스템을 발전시켜보자
1. 기본 구성

2. 사용자의 증가로인해 서버의 응답속도가 느려짐 > 서버의 스케일 아웃
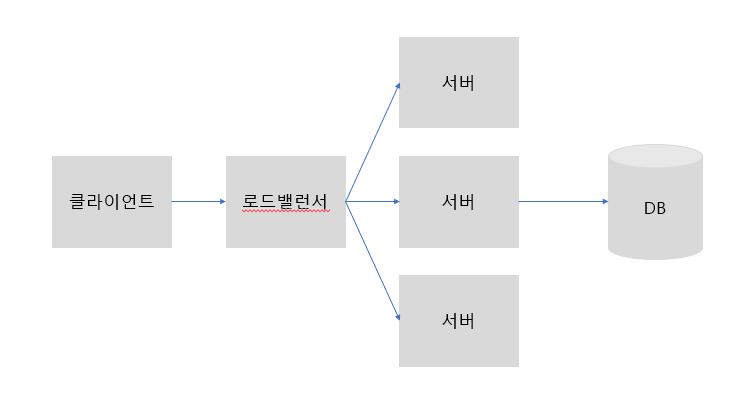
해당 서버의 부하를 분산하는건 로드밸런서(nginx...)의 역할 (RR알고리즘....등)
3. 서버를 충분히 늘렸음에도 DB응답속도가 느려짐
> 쿼리튜닝(인덱스 등), 로컬캐시 (각 서버의 메모리에 캐싱), 글로벌캐시 (redis)

캐시를 이용할경우, 주기, 만료정책 등을 고려해야함
> DB 다중화 (스케일 아웃) 아키텍처 참고 https://blog.naver.com/takane7/221440417322
웹 어플리케이션 시스템 아키텍쳐의 변화
초기 아키텍쳐에서부터 시작해 클러스터링 아키텍쳐로의 확장을 고려하기까지의 스토리를 다뤄보고자 합니...
blog.naver.com
4. 이메일, 알림과 같은 대외기관 서버와의 연동이 많이 필요 해짐, 대외기관의 응답이 느려짐
> 클라이언트는 대외기관의 응답을 기다리느라, 요청을 기다리게 됨

비동기 큐 = kafka rabbitmq...(스레드풀을 이용한 비동큐도 가능)
비동기 큐에 요청을 쌓으므로서, 대외기관과의 트랜잭션을 클라이언트 요청에서 제외 시킬 수 있음 (내 서버에 데이터에만 의존하게 됨)
비동기 큐를 사용하면, 대외기관의 적정 TPS의 맞게 요청량을 조절할 수 있음
'프로그래밍 > 대용량 시스템에 대한 이해' 카테고리의 다른 글
| 완화전략 - Backpressure, Throttling 이란? (0) | 2023.12.01 |
|---|---|
| kafka란? - 카프카 기초 다지기 1 (1) | 2023.02.19 |
| Kafka 설치 및 구동 방법 (0) | 2023.02.18 |
| Message Queue란? (0) | 2023.02.18 |
| 1. DB(데이터 베이스)는 병목지점 (0) | 2022.10.23 |